Project TAPIR: Harvesting the power of PIDs
Introduction
A recurring obligation of research institutions is reporting in order to provide a wide variety of stakeholders with up-to-date information on research activities happening at the institution. The process of data aggregation and preparation required for this is both time-consuming and labour-intensive. In the TAPIR project, we are therefore testing partially automated procedures for research reporting in the context of university and non-university research. To this end, the question is being investigated as to the extent to which the necessary data aggregation can be carried out on the basis of openly available research information using persistent identifiers.
Open data sources
At the beginning of the project, we first compiled an overview of current data sources from which we could retrieve open data about research objects via an API. A good starting point was the Registry of Scientometric Data Sources (ROSI), which had already been compiled in a previous TIB project. However, a few more data sources had come up since the last entries and so, as a thank you and to make our additional findings reusable, we have updated ROSI with eight new entries, including ROR, ORCID and OpenAlex.
Persistent identifiers
From the pool of open data sources, we only considered those that allow research information to be queried using persistent identifiers (PIDs). The advantage of using PIDs is that, in comparison to names, titles or designators, they are unique and permanent and thus there is no need to disambiguate the queried data before further processing. Furthermore, PIDs are (usually) linked to metadata that describe the referenced entities and can in turn refer to other PIDs. This enables connections to other objects to be clearly established and mapped, as is the case with so-called PID graphs.
Queries
Let’s summarise: The aim is to portray the research activities of an institution in standard reports using PIDs from open data sources. So, given a PID for an organization we are looking for a set of PIDs, each of which uniquely identifies a research output of the organization. Since research output is usually associated with authors rather than organizations, an intermediate step is needed to determine the researchers belonging to an organization, and then the research output of each of the researchers. The query of the data is accordingly two-stage, first organization-people and then further person-works. The organization is identified by its ROR, a person by its ORCID and a work by its DOI.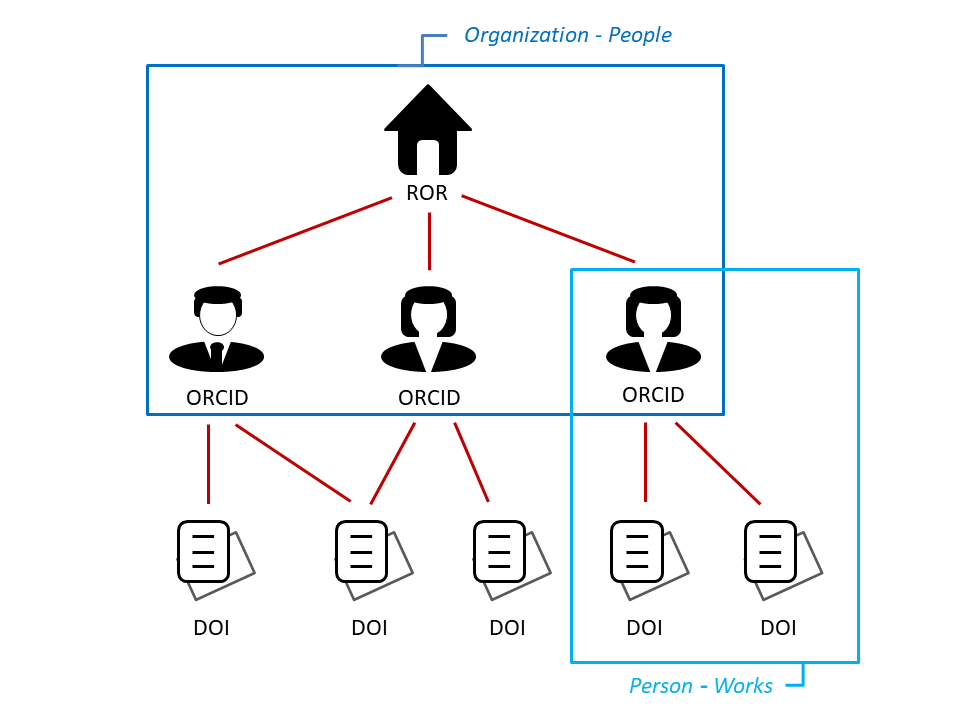 Data sources that enable both of these queries include the FREYA PID Graph, ORCID and OpenAlex. For the person-works connection, we additionally included Crossref as one of the largest DOI providers. All queries are described in reusable Jupyter Notebooks and can be found at https://github.com/Project-TAPIR/pidgraph-notebooks. The code stored there can be executed directly in the browser via the web service Binder, so you can try it out with the ROR ID of your institution or your ORCID iD. A button that opens the notebooks in Binder can be found in the description (README).
Data sources that enable both of these queries include the FREYA PID Graph, ORCID and OpenAlex. For the person-works connection, we additionally included Crossref as one of the largest DOI providers. All queries are described in reusable Jupyter Notebooks and can be found at https://github.com/Project-TAPIR/pidgraph-notebooks. The code stored there can be executed directly in the browser via the web service Binder, so you can try it out with the ROR ID of your institution or your ORCID iD. A button that opens the notebooks in Binder can be found in the description (README).
Outlook
The next step in the TAPIR project is to evaluate the queried data from the various data sources. To do this, we will compare their coverage in terms of persons and published works once with internally produced verified lists made at the institutions involved in the project, TIB and the University of Osnabrück, and then again with each other.
You can follow all developments on our project homepage https://projects.tib.eu/tapir/en or on our Twitter channel project-tapir.
Image: “Color comp” by Pablo Stanley. The Blush open license, illustrations for commercial and non-commercial purposes. https://blush.design/license