Entdeckung von Forschungstrends durch bibliometrische Analyse mit der Dimensions API
Ein Analysebeispiel: Topic Analysis in der Informatik an der Leibniz Universität Hannover der letzten fünf Jahre
In der schnelllebigen Welt der wissenschaftlichen Forschung ist es entscheidend, stets über aufkommende Forschungstrends informiert zu sein. Allerdings gestaltet sich die Gewinnung aussagekräftiger Erkenntnisse aus der Vielzahl von Publikationen als äußerst herausfordernd. Bibliometrische Verfahren, die statistische Methoden auf Forschungsergebnisse anwenden, bieten einen besonders hilfreichen Ansatz für weitere Analysen.
Sind bestimmte Themen über einen längeren Zeitraum prominent in (internationalen) Publikationen vertreten, lassen sich daraus beispielsweise Trendthemen ableiten. Deren Analyse kann wertvolle Einblicke in sich verändernde Prioritäten und neu entstehende Interessensgebiete innerhalb einer bestimmten Wissenschaft liefern. Der Nutzen für die Forschenden könnte zum Beispiel darin bestehen, dass sie ihre Forschungsschwerpunkte an aktuelle Trends anpassen und so sicherstellen, dass ihre Arbeit relevant und wirksam bleibt.
Die Herausforderungen solcher Analysen liegen nicht nur in den Aspekten und Fakten, die von den Publikationsdaten abhängen (wie Datenqualität, Datenaktualität und Multidisziplinarität), sondern auch in den Prozessen der Datenanalyse. Dazu gehören Datenerhebung, -bereinigung, -auswertung und -visualisierung. Die Datenbank Dimensions Analytics, die seit 2021 für die Universität lizenziert ist, könnte an der Stelle zielführend eingesetzt werden. Sie bietet für diese Art der Analyse gute Lösungsansätze, die es den Forschenden ermöglichen, einen effizienten Einstieg und eine zuverlässige Basis für weiterführende Analysen herzustellen.
Dimensions Analytics API
Die Dimensions API ermöglicht es, Daten aus hochspezifischen Abfragen mit einem einzigen API-Aufruf abzurufen, zu aggregieren und zu sortieren. Mit Hilfe von vorbereiteten Python Notebooks können dann komplexe Analysen durchgeführt und die Ergebnisse entsprechend visualisiert werden.
Durchführung der Topic Analysis mit dem Dimensions API Python Notebooks
1. Wie soll der Datensatz aussehen?
Für die Beispielanalyse wurden die Veröffentlichungen im Fach „Information and Computing Sciences“ der Leibniz Universität Hannover (LUH) genommen. Um die Entwicklungsprozesse der Themen nachvollziehen zu können, soll ein längerer Zeitraum der Veröffentlichungen gewählt werden, zum Beispeil die letzten 5 Jahre. Die Search Query mit dem Python Notebook sieht dann wie folgt aus:
search publications
where research_orgs.id = „grid.9122.8“ # Leibniz Universität
and year in [2017:2023]and category_for.name=“46 Information and Computing Sciences“
return publications[id+concepts_scores+year]
Concepts Found (total): 81530Unique Concepts Found: 29424Concepts with frequency major than 1: 7013
2. Was sind die besten Einstellungen (Parameter etc.), um sinnvolle Inhalte zu extrahieren?
In der Datenbank Dimensions werden sogenannte Konzepte verwendet, um den thematischen Inhalt der Dokumente zu beschreiben. Dabei handelt es sich um aus Abstract und Volltext extrahierte Substantivphrasen, die auch als Schlagwort oder Schlagwortphrase eines Dokumentes verstanden werden können.
Aus dem Datensatz von 1) wurden dann die Konzepte aggregiert und das Unique Concept herauskristallisiert. Konzepte mit sehr hoher Frequenz [1] sind in der Regel häufig vorkommende Wörter, so dass es sinnvoll ist, diese auszuschließen. Weiterhin wurden für die Relevanz der Konzepte sogenannte Score [2] und Score Average [3] der Konzepte eingeführt, wobei nur die Konzepte mit einem minimalen Average Score von zum Beispiel 0,4 berücksichtigt wurden. Dabei können diese auch je nach Anforderung der Analyse variiert und angepasst werden (siehe unten).
FREQ_MAX = 70
# Score: the average relevancy score of concepts, for the dataset we extracted above.
# This value tends to be a good indicator of ‚interesting‘ concepts.
SCORE_MIN = 0.4
# Select how many concepts to include in the visualization
MAX_CONCEPTS = 200 #@param {type: „slider“, min: 20, max: 1000, step:10}
if FREQ_MAX == 100:
FREQ_MAX = 100000000
print(f“““You selected:\n->{MAX_CONCEPTS}\n->{FREQ_MIN}-{FREQ_MAX}\n->{SCORE_MIN}“““)
filtered_concepts = concepts_unique.query(f“““frequency >= {FREQ_MIN} & frequency <= {FREQ_MAX} & score_avg >= {SCORE_MIN} „““)\
.sort_values([„score_avg“, „frequency“], ascending=False)[:MAX_CONCEPTS]
3. Konzepte mit hohen Frequenzen
Die Konzepte mit hohen Frequenzen und auch relativ hohem Average Score können dann mit einer ersten Visualisierungsmöglichkeit, einer Wordcloud, erstellt werden (siehe Abbildung 1).

Konzepte wie „artificial neural network“, „big data“, sowie „multi agent systems“, „natural language processing“ zeigen ihre deutliche Relevanz, aber auch Themen wie „anomaly detection“, „structural health monitoring“, „advanced driver assistance systems“ spielen an der LUH ein wichtige Rolle.
4. Trendanalyse: Jedes Jahr neu entstehende Themen
In diesem Abschnitt wird die Verteilung der Konzepte über die Jahre analysiert, wobei der Schwerpunkt auf den „neuen“ Konzepten jedes Jahres liegt, das heißt den Konzepten, die in den Vorjahren noch nicht aufgetaucht sind (siehe Abbildung 2).
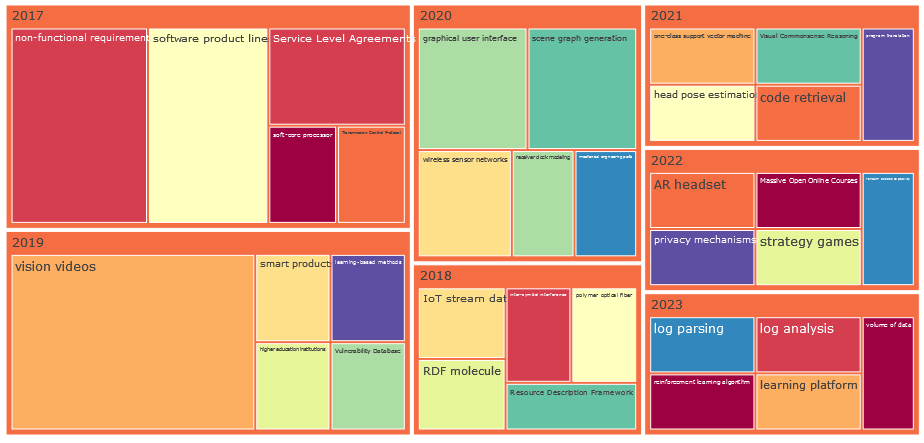
Die Interpretationen der neu aufkommenden Themen können sehr spannend und interessant sein. So könnten zum Beispiel die neuen Konzepte im Jahr 2023: „Lernplattform“, „Reinforcement Learning Algorithmen“ und „Log Parsing“ sowie „Log Analysis“ im Kontext von intelligenten Systemen, Datenverarbeitung und maschinellem Lernen stehen. Sie könnten sogar miteinander verknüpft sein, wenn zum Beispiel eine Lernplattform zur Implementierung und Evaluierung von Reinforcement Learning Algorithmen verwendet wird. Die Konzepte des Log Parsing und der Log Analysis könnten dann verwendet werden, um Einblicke in das Verhalten von Algorithmen zu gewinnen, um deren Effizienz, Robustheit und Leistung zu verbessern.
5. Trendanalyse: Themenwachstum
Es ist ebenfalls sehr interessant zu beobachten, wie Konzepte, die über mehrere Jahre auftreten, im Laufe der Zeit zu- oder abnehmen (siehe Abbildung 3).
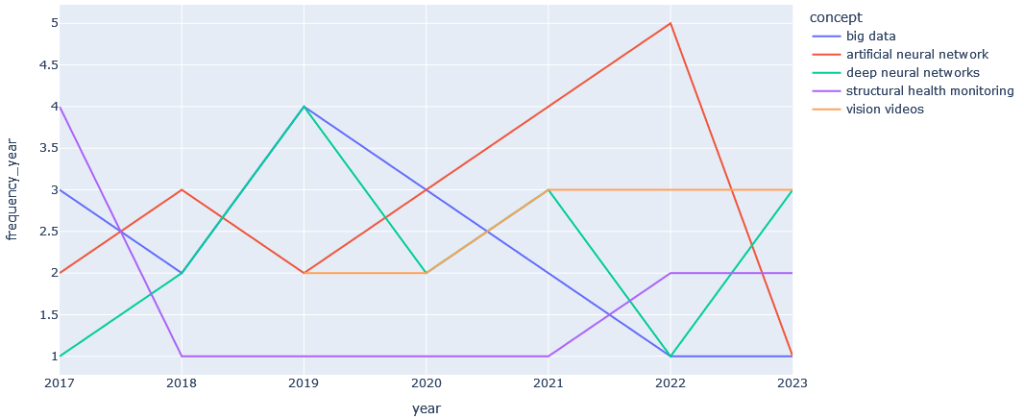
In einem relativ kurzen Zeitraum für diese beispielhafte Analyse kann man bereits erkennen, dass die Entwicklung des Themas „Big Data“ nach 2019 stetig abnimmt, während das Thema „Artificial Neural Network“ an Aufmerksamkeit zu gewinnen scheint.
Fazit
Mit dem Dimensions API Python Notebook kann ein zeitnaher und umfassender Einblick in die sich ständig verändernde wissenschaftliche Forschungslandschaft gewonnen werden. Dabei ist es nicht notwendig, einen komplett neuen Python-Code zu schreiben, sondern es genügt, das vorgefertigte Dimensions Python Notebook zu verwenden, es ggf. mit Parametern wie Publikationen, Häufigkeit und Mittelwert an die eigenen Bedürfnisse anzupassen und so interessante Konzepte programmatisch hervorzuheben und für weitere Analysen des Dokumentendatensatzes, aus dem sie stammen, zu verwenden.
Weitere Informationen zu den Themen: Bibliometrische Analyse mit Dimensions API, siehe auch „TIBgefragt: Bibliometrie und bibliometrische Analyse“ oder nehmen Sie einfach Kontakt mit mir, Linna Lu, per E-Mail unter linna.lu@tib.eu auf.
[1] frequency: how often a concept occur within a dataset, i.e. how many documents include that concept. E.g., if a concept appears in 5 documents, frequency=5.
[2] score: the relevancy of a concept in the context of the document it is extracted from. Concept scores go from 0 (= not relevant) to 1 (= very relevant). NOTE if concepts are returned without scores, these are generated automatically by normalizing its ranking against the total number of concepts for a single document. E.g., if a document has 10 concepts in total, the first concept gets a score=1, the second score=0.9, etc..
[3] score_avg: the average (mean) value of all scores of a concept across multiple documents, within a given in a dataset.

... ist Fachreferentin für Informatik und Bibliometrie an der TIB.