An automated Wikibase deployment pipeline for research data management
Intentions and methods for deploying Wikibase test and production instances at the Open Science Lab, TIB – Leibniz Information Centre for Science and Technology
As part of our work in the context of NFDI4Culture, a project aimed at setting out standards, guidelines and practical implementations of infrastructure for research data management, the Open Science Lab have been engaging with the construction of a reliable and configurable deployment process for Wikibase. The requirements themselves have grown organically based on research needs in the context of facilitating LOD management and the annotation of complex media objects, and includes significant modification from the example Wikibase installation configuration provided by WMDE. Our method of deployment has also matured from a collection of terminal commands to a fully-automated Ansible playbook.
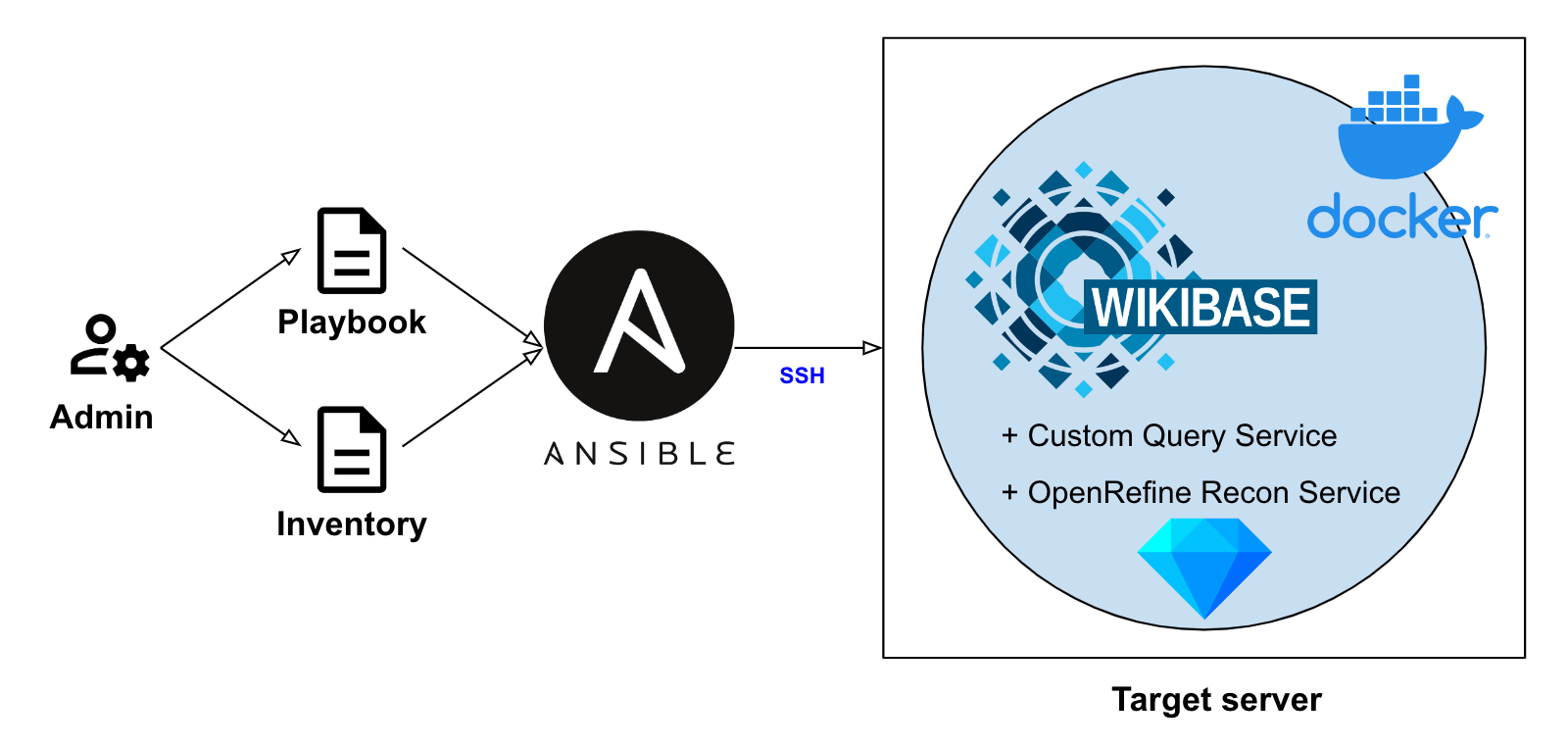
Deployment
Our entire deployment process is now orchestrated by Ansible. This is a tool intended to allow developers to deploy systems in a highly predictable manner, and is attractive as it requires that nothing is pre-installed on target servers. It is also extremely scalable: if a playbook can write a deployment to a single instance, it can write to a hundred.
The time-saving aspect of Ansible has also been crucial, as the deployment playbook now contains a number of discrete stages, from installing prerequisite tools, building custom containers and performing post-installation configuration. We have included full NGINX configuration, including automatically requesting SSL certificates as, although we no longer use this role in our own instances, this has been retained here as likely useful for other users who wish to deploy a proper HTTPS setup.
Within the playbook, it is worth breaking down what each of these roles are doing:
-
User
The process begins by creating a non-root user account on the server and migrating the required SSH keys to allow direct login to the new account. -
Nginx
NGINX is installed, certificates and configuration generated and the system is restarted ready for use. In the interests of pursuing idempotency, certificates are generated only if they do not exist. Users should be aware while undertaking deployment testing that there are rate limits imposed by LetsEncrypt which are easily reached. -
Docker
This stage installs Docker and Docker Compose, which are required for the various containerised components of the installation. Containerisation is the process of wrapping an application within a generalised and predictable environment, which avoids the historical issues with applications behaving differently when installed on different systems. -
Custom Query UI
Inspired by the excellent work undertaken by Rhizome customising their own query interface, we have forked an instance with further modifications. These include changes to stylistic elements as well as adding custom prefixes for query building. Currently, this is deployed by submitting templated configuration files and building the Docker image directly as part of the playbook, but we will shortly publish this as a versioned container with configuration applied post-build. -
Wikibase
Wikibase itself is then constructed. This is achieved by writing the necessary templates and scripts to the target server and starting all Docker containers from a single Docker Compose configuration file. Much of this Docker configuration is unchanged from the default, with a few key alterations to allow for HTTPS support. The Wikibase configuration file has been modified to include extensions for hosting local media, requiring account sign in and approval prior to making edits, email server configuration to allow Wikibase to issue notifications, and a custom namespace for „Description“ pages. The latter serves the common need in research data management scenarios to work with long-form natural language texts, which requires storage separate to the structured data statements. There are also the typical style updates: logo, icon and Wikibase name. -
ConfirmAccount
Although ConfirmAccount has been requested by the Wikibase configuration, the extension itself must also be installed. This role downloads the appropriate release, unarchives and places it in the required location. The role also runs the required maintenance PHP script to update the Wikibase SQL database. -
Prefixes
Some prefix updates must be submitted to the query service configuration to allow for the customisation deployed as part of the built query user interface. -
Reconcile
The final stage of the deployment is to enable a reconciliation endpoint for writing data from OpenRefine to our Wikibase instance. Prior to building the application itself, it is necessary to add mandatory edit tags for multiple versions of OpenRefine, which is achieved via a small Python script. After this, the service configuration is written with instance specific information, and the service is launched.
Production and testing architecture
As with other TIB projects, each Wikibase deployment comprises discrete instances for production, testing and development work, written to distinct Debian servers. The advantage of deploying via the same Ansible playbook to each of these servers is that testing and development work can take place in environments identical to the production instance. Concerning data synchronisation, this is performed using a SQL database snapshot process and is enacted periodically from production to test instances.
Maintenance
Maintenance of the Wikibase deployment is controlled by a separate playbook, which manages the automated snapshotting process to ensure that data will be retained in the case of catastrophic server failure, or to facilitate regular database overwriting operations. A planned extension of this playbook will be the incorporation of system monitoring tasks to ensure that the services are responding as expected. This playbook will also be handed over to a scheduling system like Apache Airflow to manage regular operation without human interaction.
The use of Ansible is also useful beyond deployment, as system upgrades to Mediawiki, Wikibase and other containerised components can be consistently directed to all relevant servers. In this way, maintenance remains a sustainable task even when the number of running instances is scaled.
Outlook
The process described above has allowed us to deploy instances of Wikibase which are specially customised to meet the needs of research data management use-cases with minimal effort and with confidence that the resulting services will be stable and ready to use. Future efforts will focus on additional strategies for managing multiple deployments, adding improved system monitoring and the incorporation of further tools and configuration changes as driven by project requirements.
0 Antworten auf “An automated Wikibase deployment pipeline for research data management”