Semantifying the IPCC Reports: A Hackathon
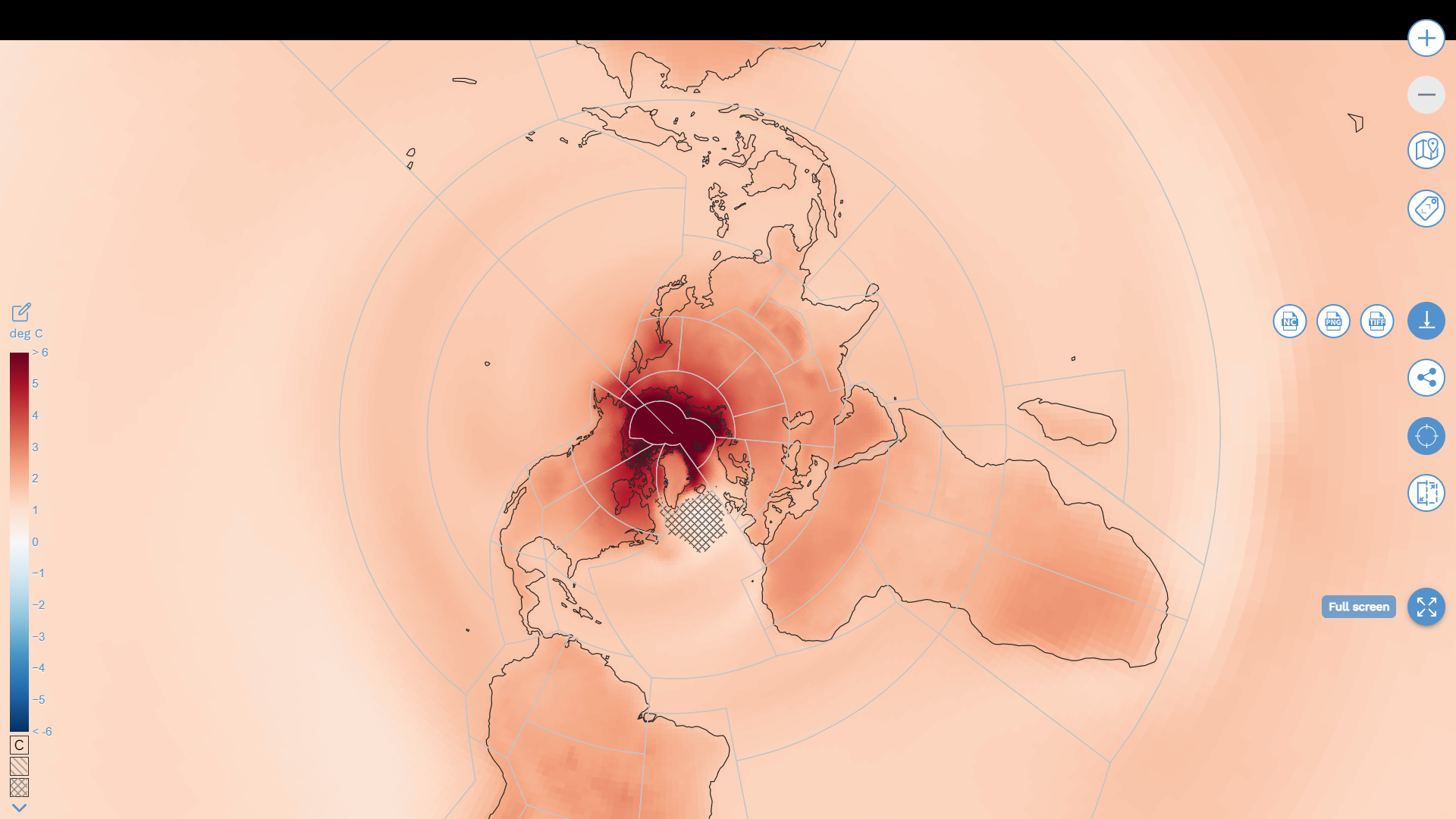
Formats For Future is a distributed and asynchronous hackathon taking place over the International Open Access Week 2022, 24-30 October, to support the open research group #semanticClimate in liberating the reports of the Intergovernmental Panel on Climate Change (IPCC) and other climate change scientific knowledge.
International Open Access Week 2022 – October 24-30
Sign up to take part: EventBrite
Information: Formats For Future
Join the discussion: https://github.com/petermr/petermr/discussions/
#semanticClimate #FormatsForFuture
semanticClimate is driven by a group of young Indian scientists volunteers who are developing tools and processes to semantify the more than 10,000 pages IPCC reports for use across academia, by the wider public and, for citizen science projects. Wikidata is used to bring together a variety of ‚linked open data‘ resources in a series of hackathons that started with the ‚Hackathon Piage‘, Geneva, in June 2022 and currently run through to the summer of 2023.
About the IPCC reports
The IPCC Sixth Assessment Report (AR6) published earlier in 2021-22 comes to nearly 10,000 pages:
- Working Group I: The Physical Science Basis;
- Working Group II: Impacts, Adaptation and Vulnerability, and;
- Working Group III: Mitigation of Climate Change.
Its publishing makes the same mistake that scientific publishers continue to make of publishing only as PDF – trapping the content like an insect in fossil amber – a wonder – but immobile and dead. The PDF is ‚read only‘ it can’t be translated into different languages, queried to see where climate models have been used, give up its linked supporting data, or easily share all its citation – or let alone engage with the wide variety of data science tools available.
Benefits of semantification
Semantification of the IPCC reports is the way to expand the reports use in modern information and data science systems. The vision, idea, and operational technology to perform this work are not new. Below are just a few example use cases:
- If you wanted to ask the question: ‚How many women scientists contribute to the recent Sixth Assessment Report and its referenced literature?‘. The semantic process can answer such questions by combining machine intelligence and input from scientists familiar with gendered names to produce a linked open data list, which could then be expanded to associate fields of study, institutions, etc.
- The Assessment Reports has a robust structural method which divided the study into subjects, then looks at likelihood of impacts, and possible mitigations to lessen the effects of climate change. If this structure was semantified then the contents could be more efficiently used and presented. As an example if scientists, industry, government, or the public wanted to make use of the report for example in a region ‚rapid decarbonization plans for energy‘ then they could find relevant information and supporting material.
Linked open data: Semantic queries
The #semanticClimate group is using modern publishing tools to liberate the IPCC reports and ‚linked open data‘ based around Wikidata is key to this process.
The IPCC reports cover many subject areas and relate to a vast amount of scientific papers, 14,000 just for Working Group I, Climate Change 2021: The Physical Science Basis. As well as having a scenarios and metrics for ranking of climate change – climate models, likelihood or events, best estimates, and short to long term outcomes – that is intended for use in policy such as the Paris Agreement for real world application.
In essence the IPCC reports have a lot of relationships that if they were mapped and could be queried would help make the explicit knowledge more usable and help reveal other information and insights.
This is where ‚linked open data‘ (LOD) comes into its own as these relations can be embedded in the documents themselves and then linked and processed with other open data. If we wanted to find out how many women scientists from the Global South contributed to literature used by the IPCC reports then the LOD could do this job if the authors were annotated as in the figure below – as persons living in a location. Using the #semanticClimate technology and community this type of enrichment can already be done.

How the hackathon works
The hackathon is designed to be asynchronous so that individuals and groups can work at their own pace over the week – working either to just put in a couple of hours work or for longer. There are two goals:
- first to build ‘dictionaries’ for chapters, and,
- second to get feedback and better document the workflow so more people can take up the process and the scale the semantic work.
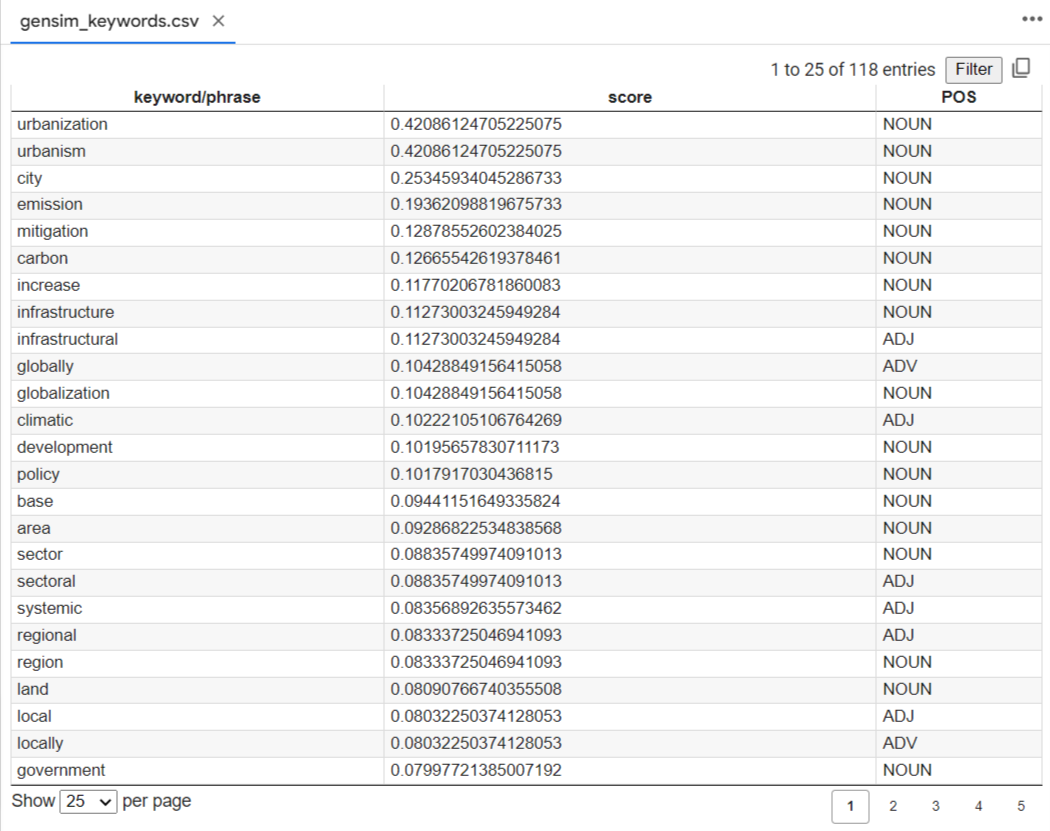
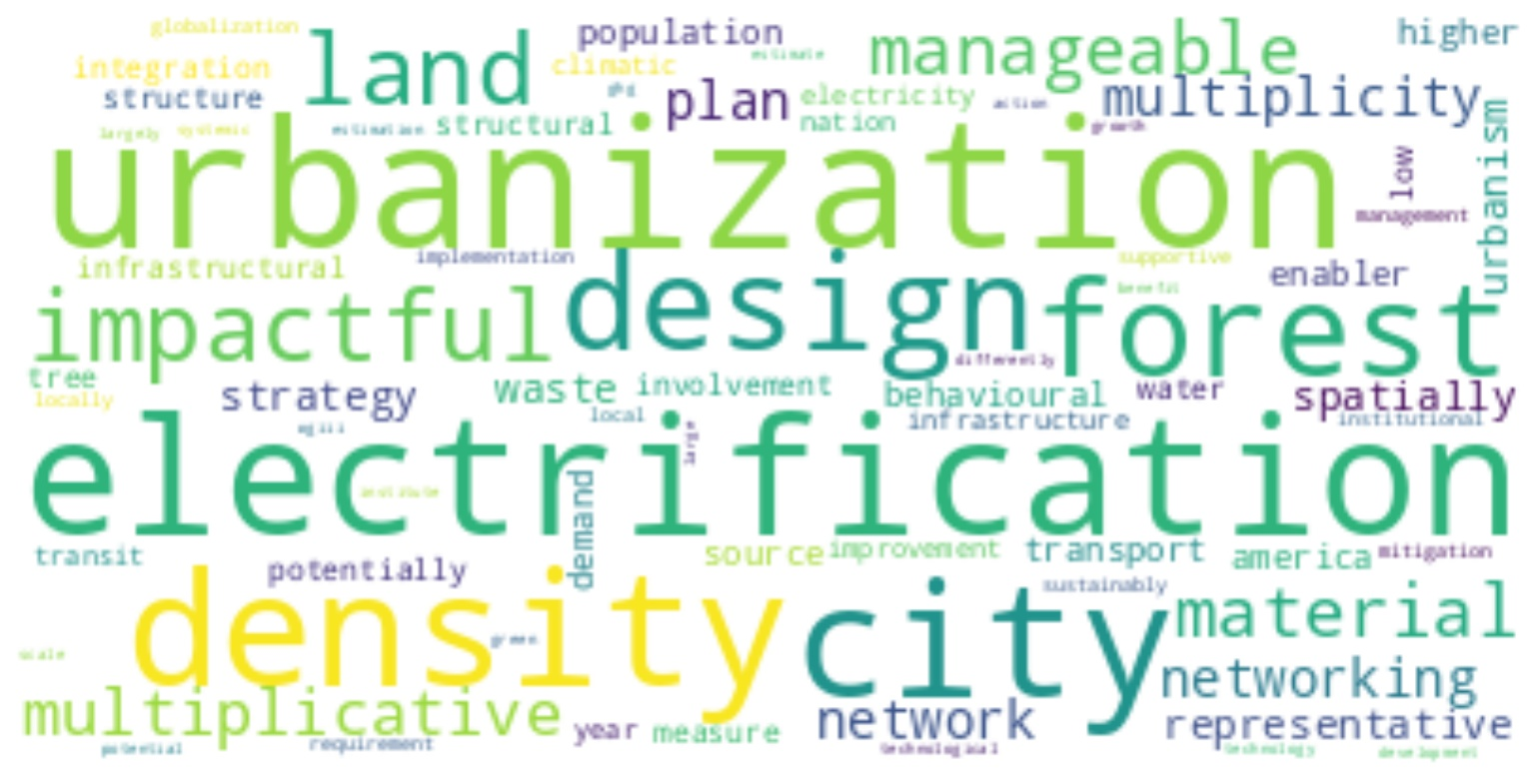
The dictionaries are the important terms related to a chapter and can be linked to Wikidata entries. The dictionaries are made by running a ‘text and data mining’ (TDM) word frequency process on a chapter and then the users selecting the key terms. After several rounds of this process, with discussion about the dictionary refinement – the end results can be taken forward and used to annotate a full text version of the chapter. Annotation, here means marking up the terms with their Wikidata information into the full text document. Other pre-existing dictionaries with either controlled vocabularies, ontologies, or special terms or acronyms are used to annotate the chapters as well.
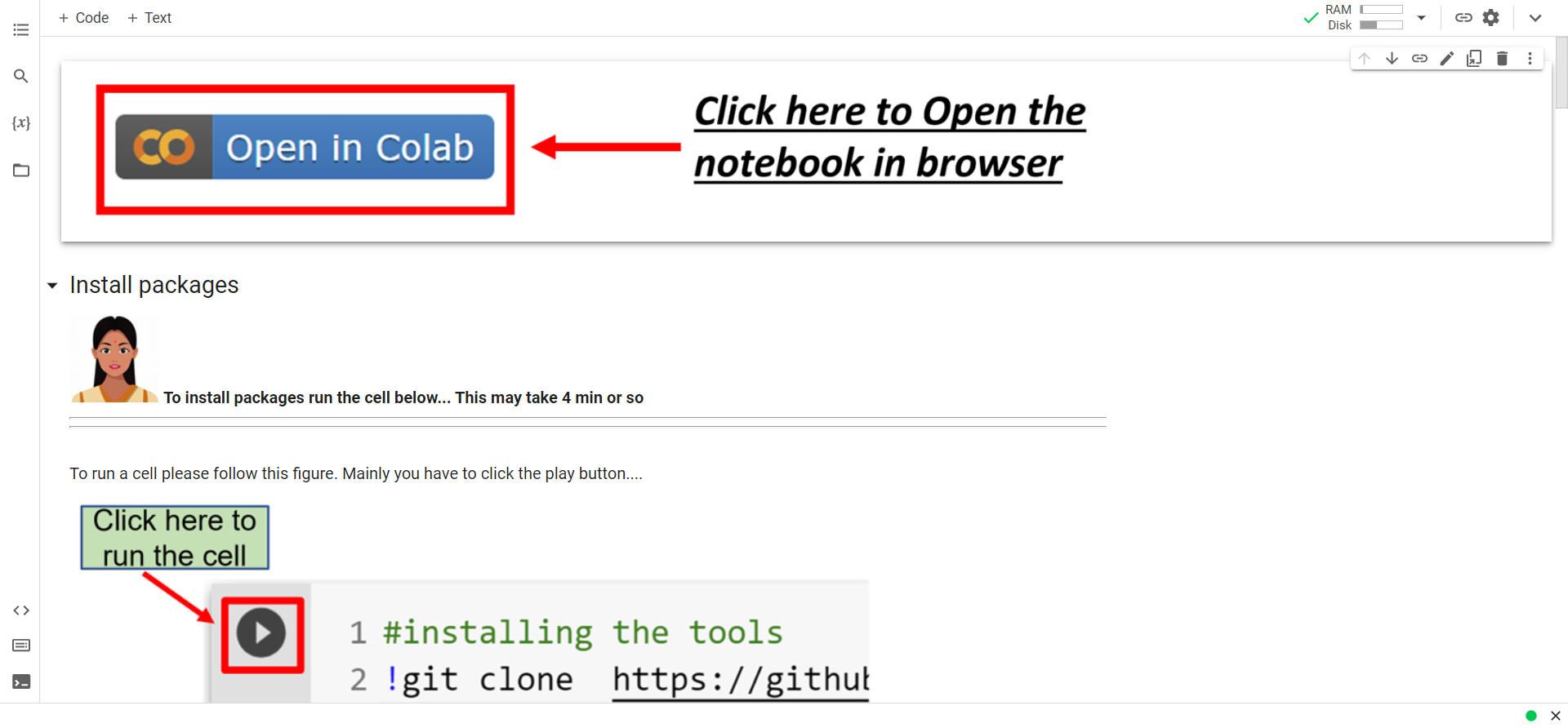
The TDM process is run using a Jupyter Notebook on the Google platform Colab, so there are no installation steps to be taken and results can be stored straight to Google Drive.
How to get involved
There is an open invitation to get involved and contribute and learn about how #semanticClimate works. The toolset is based on well established open source software. There are clear instructions and a support team. Volunteers can join teams for the creation of dictionaries, help with documentation and creating a clear set of guide information, or join as Chapter Champions to recruit and lead teams for dictionary creation. Information is available covering the Jupyter Notebooks Colab use, and videos from ‚Post-Hackthon Pitch to SDG Accelerator‘.
Formats For Future
As part of the hackathon the question is being asked:
What should a modern scientific workflow look like, what are the digital objects that should be produced from such a workflow, and how could the IPCC integrate these new practices and technologies without disrupting their work?
Formats For Future will explore these questions and produce a working paper for wider community consultation outlining the options for the type of technology and practices that could be put in place. Important to such design processes is to build in open science values from the start as outlined in the UNESCO Open Science Recommendations (page 17). Otherwise, the knowledge system will only replicate societal imbalances and blind spots which clearly undermine the whole scientific endeavour. Two glaring example of putting these values forward would be to address the following: Firstly, Global south scientists are excluded from contributing to the IPCC working groups because of neocolonial publishing practices, and secondly, not properly considering the wider public outside of academia as readers or users of the IPCC reports.
The Open Access week Formats For Futures hackathon is only one small step towards a new type of semantic open science publishing, but it sits on decades of work by the scholarly open source and open science communities. #semanticClimate have the current roadmap outlines here in their technical strategy page and Formats For Future supported by the Single Source Publishing Community and other partners will be looking at how to update the wider workflows parts – all to aid greater access to the IPCC reports and their findings.
International Open Access Week 2022 – October 24-30
Sign up to take part: EventBrite
Information: Formats For Future
Join the discussion: https://github.com/petermr/petermr/discussions/
#semanticClimate #FormatsForFuture
 This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.

… is the research in NFDI4Culture - Data Publication - and project lead on #NextGenBooks project at the Open Science Lab, TIB – German National Library of Science and Technology. Board member of FORCE11 and member of the LIBER Citizen Science Working Group.
2 Antworten auf “Semantifying the IPCC Reports: A Hackathon”