Ami Meets Ada: Connecting IPCC Reports with City Climate Change Plans
The FSCI 2023 Climate Change Hackathon prototyped a search and publishing service to help contributors to city climate change plans create referenced readers from IPCC Climate Reports
The ‘Climate Knowledge Hunt Hackathon’ took place over five days of the FORCE11 Scholarly Communications Institute (FSCI) August 2023 and was led by the semanticClimate open research community. The prototype was one of several projects carried out in the hackathon around the climate change topics of cities, mountains and glaciers, and food security.
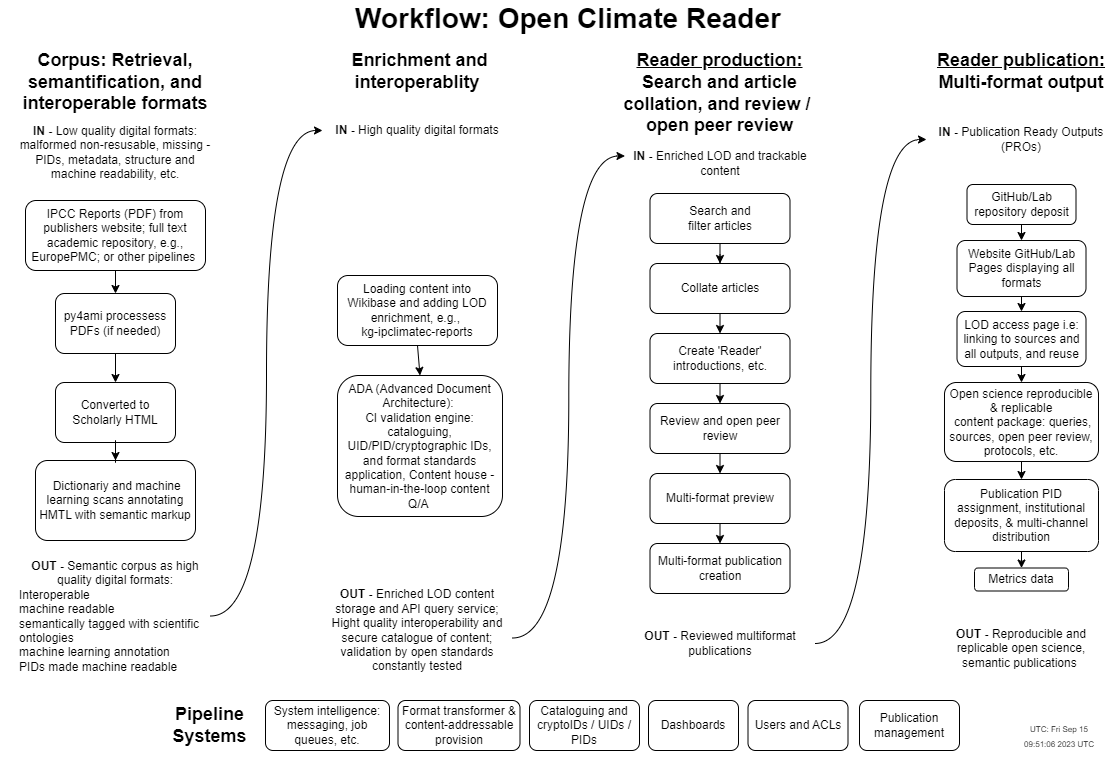
The prototype brought together two open-source software pipelines py4ami and the ADA Semantic Publishing Pipeline (from the Open Science Lab, TIB) combining them to make a service where climate plan contributors could ask questions of IPCC Climate reports, and then from the search results collate the texts into a referenced reader as in the mock-up prototype that was made City – Open Climate Reader.
The goal of the Open Climate Reader project is to create a web service for easy knowledge access of IPCC Reports for use in city climate change plans and their supporting cultural and educational projects.
How it works!
Firstly, py4ami software works by breaking down the IPCC Reports into the smallest parts possible, for example — sentences, acronyms, section headers, images, citations — and semantically tags each part. This tagging then allows machine readability and use of machine learning tooling, which in effect unlocks the content for findability and analysis, such as search results, knowledge graphs, and use of scientific ontologies
Secondly, the ADA software pipeline for publication production and publishing takes the outputted content from py4ami and automatically typesets a reader as multi-format (web, docx, ebook, and source), adds review processes, and publishes the package on GitHub/Lab Pages.
What progress was made in the hackathon?
This was the first round of prototyping for the project and so it acts as an exercise to understand the workflow components needed to make the system work. A mockup proof of concept prototype was created which asked general city climate plan questions of the IPCC reports. Technically two parts of the system were worked on: firstly, with py4ami the gap between the ‘text data mining’ and output of HTML content was closed so that handling a query like ‘What role do renewable energy sources play in city climate plans?’ could be done more efficiently; and secondly, for ADA a first-go of an HTML to Markdown conversion was put in place.
What‘s next?
If you’re interested in helping out on the next round of prototyping by volunteering or contributing resources check out the semanticClimate discussion and project tasks on GitHub.
A working prototype for Open Climate Reader
The round of work from the hackathon allowed the team to see the gaps in the system and what would need to be put in place to have a working prototype — meaning we now have a roadmap. There are four priority areas to work on for a working prototype:
- How to smoothly move contributors‘ questions into the search and content retrieval process?
- How to create citation links to sections of the source material which are only held as PDFs and so can’t be targeted on a granular basis? Wikibase has already been used by semanticClimate and is one route forward for this.
- Further automating the conversion of HTML content to Markdown.
- Adding a review process to the collated reader content.
AI prototype (self-hosted)
AI Open Climate Reader is a proof of concept software prototype that can query scientific corpora and create ‘reader’ publications using AI with added human review. The types of ‚reader’ publications it would make are: Referenced summaries, suggestions for literature, and guides on specific topics. The publications would have all the references collated as full text in the publication.
- Deposit content in a Wikibase instance as with the AR6 IPCC Report in an earlier hackathon. New Wikibase instances managed as a Wikibase4Research service.
- Then self-hosted AI would be used to create the publications — example AI models are falcon-7b, falcon-40b-v2, and vicuna-33b-v1.3.
- Review and multi-format publishing is then run to create a reproducible and replicable semantic publication on GitHub/Lab Pages using the ADA Semantic Publishing Pipeline which harnesses Fidus Writer and its Open Journals System JATS editor plugin for review.
Thank yous
Thank you to all the hackathon participants, the semanticClimate team and especially Summer 2023 Interns and scientific staff from the National Institute of Plant Genome Research (DBT-NIPGR), New Delhi, India, who contributed to the ‘mockup’ prototype: Cities (Mahvish Fatma, Renu Kumari, Waheb Mehdi), Mountains and Glaciers (Shiwani Yadav), and Food Security (Yasin Jeshima, senior scientist from ICAR-NBPGR). Thank you to Peter Murray-Rust, Gitanjali Yadav, and Shweata Hegde for pushing semanticClimate forward and making dreams become reality. To Simon Bowie of the COPIM project and Centre for Postdigital Cultures – Coventry University, UK for the code contribution for the HTML to Markdown converter. ADA Semantic Publishing Pipeline is from the NextGenBooks service provided by the Open Science Lab, TIB, and supported by NFDI4Culture research as part of the National Research Data Infrastructure Germany (NFDI).
Note
The initial prototype attracted the interest of AI enthusiasts and quickly pointed a route for using AI in assisting authors in creating readers, see the second post in the two part blogpost which maps out a next step prototype: AI Open Climate Reader.

… is the research in NFDI4Culture - Data Publication - and project lead on #NextGenBooks project at the Open Science Lab, TIB – German National Library of Science and Technology. Board member of FORCE11 and member of the LIBER Citizen Science Working Group.