Open access for cultural heritage data
There are many aspects that concern the provision of open access to cultural heritage data – from the digitisation of material assets, to the preparation of descriptive, administrative and technical metadata; from the provision of access points to machine-readable, structured metadata to the support for collaborative work environments with accessible user interfaces (for archivists, scholars and general public alike). The presentation of digitised cultural heritage via different media formats and the allowance to view, compare, annotate media are yet further aspects that have been focus points for digital humanities and information science professionals. Addressing these aspects with a view to long-term sustainability also depends on open standards, open source code and active maintenance of shared resources over time – preferably independently from the short-term cycles of research funding.
The work of the NFDI4Culture team within the Open Science Lab at TIB is concerned precisely with the long-term sustainability of open access to cultural data and seeks to assist cultural heritage communities in iteratively developing tools that closely match community requirements and allow flexible adjustments for different use cases. More specifically, the tools address three core areas of open access: access to metadata, access to media, and access to domain-specific terminologies and controlled vocabularies.
Access to metadata
We address challenges for structuring, collaboratively editing and then accessing cultural data via our Wikibase4Research services. Wikibase is an open source software package from the Wikimedia family of applications. It allows the storage and management of Linked Open Data (LOD), including access to a SPARQL endpoint, besides featuring other common characteristics of wikis, such as collaboration and version control features. The core software is released and maintained by Wikimedia Germany, who also use it to run Wikidata, their vast, encyclopedic public database of LOD. Both Wikibase and Wikidata play an important role in the world of open data for GLAMs (galleries, libraries, archives and museums), as we have written about previously on this blog.
With the Wikibase4Research service, we offer a bundle of additional extensions (such as this one for local media file management, or this one for improved RDF mappings) and resources (such as a culture-domain-specific data model) to suit the needs of research and cultural institutions, that may require greater control over their data compared to the fully open and public environment of Wikidata, or the generic release of Wikibase. We also offer support when it comes to modeling data and ensuring interoperability with established cultural metadata standards. We balance the flexibility and “open world” scenario of the Wikibase software, where users can create all entities and relations from scratch, with the needs of cultural data publishers and researchers to remain interoperable with a range of systems and standards. Current projects we are working on include a database of photographic papers for the Foto Museum in Antwerp, and a media preservation project focused on the ‘90s artistic network TheSwissThing with the Critical Media Lab in Basel.
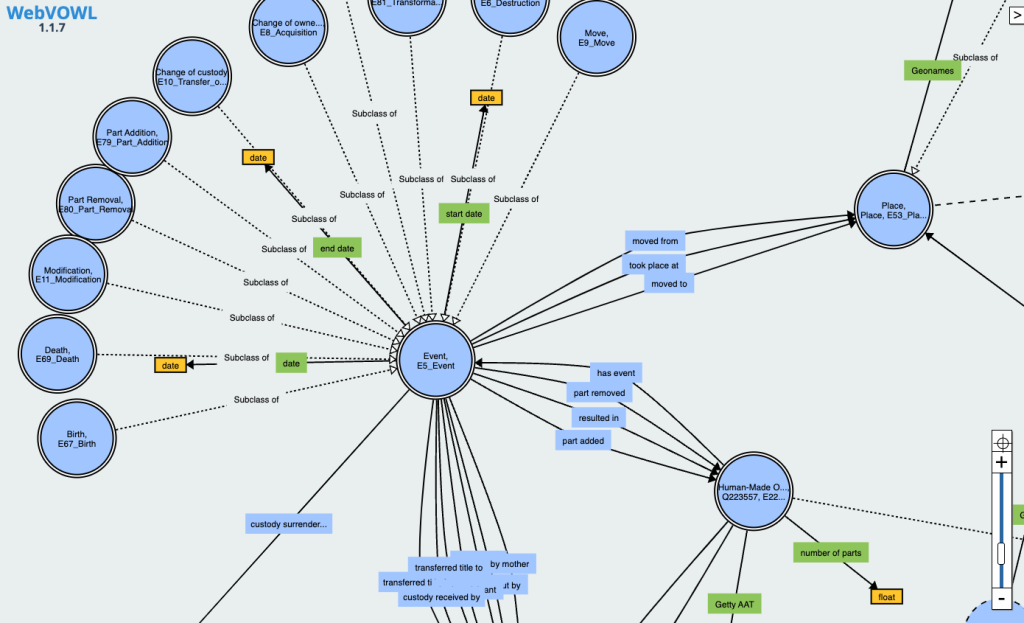
Access to media
Wikibase allows us to use structured data statements to describe cultural heritage objects in great detail. It can also store media files such as images or PDFs, but it is not designed to accommodate work with more complex files such as 3D scans or reconstructions, video or audio out-of-the-box. At the same time, presenting heterogeneous media formats alongside detailed cultural context is an important requirement for opening access to cultural data online. This is where the Semantic Kompakkt service comes in. Not a single tool, but a toolchain and workflow pipeline, the service draws upon data stored in a Wikibase instance, but adds in the capabilities to display and store various media formats, to curate media collections and to collaboratively annotate media. These additional features are made possible thanks to Kompakkt, an open source tool originally developed within the Department for Digital Humanities Department at the University of Cologne.
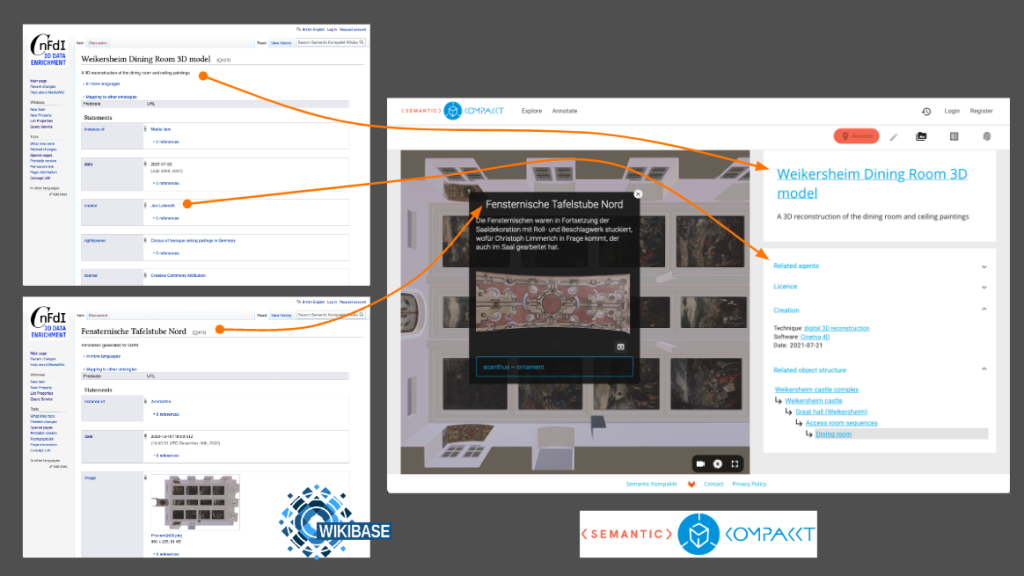
Kompakkt’s particular strength lies in the possibilities to annotate 2D and 3D media in a standards-compliant way (CIDOC-CRM, W3C Web annotation standard). Kompakkt’s original data model is mapped to Wikibase, so that all data (objects, media representations and annotations) can be stored in Wikibase and thus made accessible via the API and the SPARQL endpoint. Like Wikibase, Kompakkt is developed and maintained as an open source tool with a distinct community of scholars and developers around it, and Semantic Kompakkt joins this community with a view towards long-term sustainability securing resources not only via NFDI4Culture, but additional third-party funded projects as well. Currently we are working with the Research Centre for Manor Houses in the Baltic Sea Region at the University in Greifswald on a large-scale digitisation and historical research project focusing on art history and architecture data around manor houses.
Access to terms
Last but not least, the user workflows to structure cultural metadata and annotate media rely heavily on the use of standard terms and controlled vocabularies when it comes to providing better access to data – that is making it easier not only to find, but also reuse data. As pointed out in workshops and community consultations, using controlled vocabularies remains largely a manual task for cataloguers and researchers who need to match the correct terms in their metadata or textual description to the desired unique identifier from sources like Iconclass, GND, Getty AAT etc.
To bridge the gap between tools for cataloging metadata and tools for terminology search, we developed the Antelope service (Annotation, Terminology Lookup and Personalization). The service integrates the existing tool Falcon 2.0 to search Wikidata and DBpedia terms with additional search and results display functionalities across the most common terminology sources used in the cultural field, including the ontologies in TIB’s Terminology Service. Further features include entity linking for longer text pieces and soon also automated image annotation (thanks to collaboration with the iArt project). The web interface of Antelope is meant to serve as a demonstrator of its capabilities, but the possibility for direct integration into third-party cataloging software is where the real gains for users can be seen. We have planned integration both with stand-alone Wikibase instances and with Semantic Kompakkt. Besides multi-source terminology search, the entity linking and image annotation features introduce automation to user workflows without the requirement for in-depth data science or machine-learning knowledge. In this case, opening access to data also means opening access to new tools and workflows that may be less readily available to researchers in the humanities and cultural heritage field.
This latter point is also an important part of our mission as NFDI co-applicant, namely to improve access to and further develop customised tools for our communities, and to make them available in a long-term manner. Sustainability is also ensured through our continuous free and open source software (FOSS) community engagement, both in the Wikibase Stakeholder Group and in other contexts (e.g. the FOSDEM conference).
All of our tools are made available openly and we encourage interested parties to follow development via our Gitlab issue boards. Contributions in terms of feature requirements, code development or bug reporting are always welcome.

Dr. Lozana Rossenova ist Mitarbeiterin im Open Science Lab der TIB und arbeitet im Projekt NFDI4Culture in den Bereichen Datenanreicherung und Entwicklung von Wissensgraphen. // Dr Lozana Rossenova is currently based at the Open Science Lab at TIB, and works on the NFDI4Culture project, in the task areas for data enrichment and knowledge graph development.

... ist stellvertretende Leitung des Open Science Lab der TIB und hat eine Professur an der Hochschule Hannover für Vernetzte Daten in der Informationswissenschaft.
What are the implications of using Wikibase and Wikidata for managing cultural heritage data?
We discuss the implications further in this blog post: https://blog.tib.eu/2022/03/17/wikidata-and-wikibase-as-complementary-research-services-for-cultural-heritage-data/